
The Machine Perception and Cognition group occupies a distinctive position at the intersection of applied and foundational AI research. It is firmly motivated by practical problems (ca. 80% of our research is joint work with practice partners), yet consistently engages fundamental questions about, e.g., what data science is, how natural intelligence works, and what ML’s stochastic nature means for safety, publishing at top venues regularly (ICML, Nature Scientific Reports, Pattern Recognition, AI and Ethics etc.). Below is a summary of some defining traits that emerge consistently across the full publication record of >100 papers from >20 years (as of April 2026), serving as a key to our work. It is geared towards fellow researchers & engineers.
TOC
- Characteristics our work
- Research lines
- Examples of translation into practice
- Main scientific contributions
- Ideas we’d love to work on more in the future

Characteristics our work
Research lines
Being motivated by real-world pattern recognition problems (how perceptions are formed from sensory input and cognitively translated into reasonable actions) leads to a suprinsingly broad field of use cases and industries amidst a stable core of methodological focal points. Here’s an overview of sub-disciplines our inquiry contributes to.
Industrial AI applications
~2019-ongoing: applied programme across multiple industrial domains

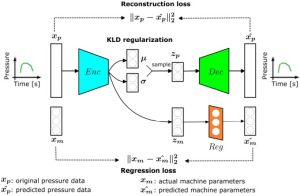
A broad programme applies ML, including RL and representation learning, to industrial problems like control and monitoring. Domains include visual quality control (ANNPR’18 invited paper), predictive maintenance (Beyond ImageNet chapter), rail traffic (SDS’20: RL-based train rescheduling), building energy optimisation (ANNPR’24), injection-moulding process monitoring (SDS’24c), industrial process control via world models (SDS’25a), and geothermal reservoir uncertainty quantification (Geothermics’24). The iScience’25 paper synthesises lessons on human-AI interaction in safety-critical infrastructures, introducing co-learning as a development paradigm.
| Paper | Key finding / message |
|---|---|
| Tuggener et al., SDS’26 | Production text-classification requires engineering beyond model accuracy: class imbalance, domain terminology, and distribution drift require a data-centric pipeline to bridge the POC-to-production gap. |
| Bolck et al., Frontiers Robotics & AI’26 | Safety certification of AI in UAVs demands dedicated testing infrastructure; the LINA framework provides structured validation pipelines addressing AI-specific certification challenges. |
| Lanfant et al., BHM’25 | A 3D-Master-derived KPI quantifies the impact of customer data quality on additive-manufacturing cost estimation, enabling earlier economic feasibility checks in the design stage. |
| Mussi et al., iScience’25 | Human-AI teaming in safety-critical systems requires trust calibration, explainability, and explicit workload allocation; co-learning as a development paradigm addresses these jointly. |
| Yan et al., SDS’25a | A JEPA-based world-model with contrastive disentanglement enables fine-grained industrial process control from very limited real data, validated on injection moulding. |
| Yan et al., SDS’24c | Data-driven VAE process monitoring with dynamic calibration achieves AUC=0.998 and 100% anomaly detection in injection moulding, outperforming manual operator-defined boundaries. |
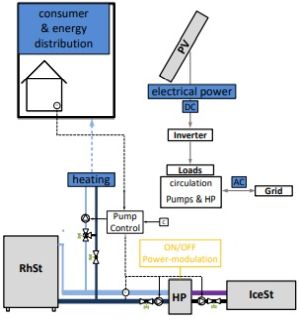
| Bolt et al., ANNPR’24 | RL building-energy control avoids MPC modelling costs; a mixed-agent PPO approach accelerates learning and substantially reduces primary energy consumption. |
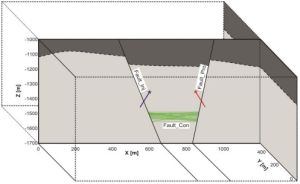
| Dashti et al., Geothermics’24 | Small structural-model variations cause large geothermal output variation; ML ensemble uncertainty quantification handles this nonlinearity reliably from sparse borehole data. |
| Yan et al., IEEE Access’23 | Survey of deep transfer learning for industrial anomaly detection: simple, tried-and-tested design patterns dominate; unsupervised/semi-supervised learning is unavoidable given scarce labels. |
| Luley et al., SDS’23 | Data-centric AI (DCAI) (i.e., systematic engineering of training data) can help overcome AI-adoption obstacles for SMEs; a process of how to do DCAI practically is introduced. |
| Battaglia et al., APL ML’23 | A deep-ensemble inverse model estimates physical solar-cell parameters from electroluminescence images; training on synthetic data transfers to real measurements, making uncertainty quantification essential. |
| Knapp et al., SDS’21b | XGBoost is a competitive, interpretable alternative to neural networks for estimating organic semiconductor device parameters from sparse measurement data. |
| Simmler et al., SDS’21a | Inaccurate or incomplete labels are a major but underappreciated bottleneck in industrial DL vision; label-quality mitigation techniques recover substantial performance. |
| Roost et al., SDS’20 | Multi-agent RL improves train rescheduling; sample efficiency and inter-agent communication are the key bottlenecks for real rail deployment. |
Document recognition & optical music recognition
~2017-ongoing: dedicated dataset and methods programme




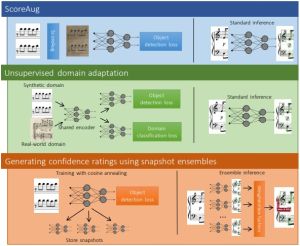

An ongoing programme addresses document recognition, i.e., the computational reading of document images like printed musical scores. The DeepScores (ICPR’18a) and DeepScoresV2 (ICPR’20) datasets are among the largest for tiny, densely packed object detection, enabling systematic benchmarking on musical notation. The associated Deep Watershed Detector (ISMIR’18) demonstrated a novel instance segmentation approach for overlapping small objects. A 2024 TISMIR journal paper reports real-world deployment, showing a substantial performance gap on digitised historical scores. Parallel work applied FCNNs to newspaper article segmentation and CNNs to formula detection and recognition. A new preprint draws on this background and introduces a new theory and first empirical results towards building document foundation models beyond optical character recognition (OCR) also for complex document typers like floor plans and engineering drawings.
| Paper | Key finding / message |
|---|---|
| Meyer et al., arXiv’25 | Treating document recognition as end-to-end structured-record transcription, and not as isolated detection, yields principled inductive-bias rules enabling document foundation models beyond OCR. |
| Schmitt-Koopmann et al., IEEE Access’24 | A data-centric approach with the FormulaNet benchmark shows annotation consistency matters more than model architecture for printed mathematical formula recognition. |
| Tuggener et al., TISMIR’24 | Domain adaptation and confidence-rated outputs are the key enablers for deploying OMR on real scanned scores; benchmark accuracy on rendered scores still over-predicts real-world performance. |
| Schmitt-Koopmann et al., IEEE Access’22 | FormulaNet is the first large-scale benchmark for printed mathematical formula detection, exposing systematic weaknesses of off-the-shelf detectors on this task. |
| Tuggener et al., ICPR’20 | DeepScoresV2 adds detailed annotations for 135 classes including non-fixed-size symbols, enabling more rigorous benchmarking of dense small-object detectors for OMR. |
| Elezi et al., WoRMS’18 | Combined DeepScores and Deep Watershed Detector provide a consistent benchmark+method platform; class-specific evaluation reveals residual challenges in polyphonic scores. |
| Tuggener et al., ISMIR’18 | Energy-based instance segmentation via watershed post-processing achieves state-of-the-art on polyphonic music object detection and generalises to handwritten notation without retraining. |
| Tuggener et al., ICPR’18 | Standard object detectors (YOLO, SSD, Faster R-CNN) fail systematically on tiny, densely packed objects; DeepScores makes this failure mode precisely measurable at scale. |
| Meier et al., ICDAR’17 | FCNNs segment printed newspaper pages into semantically coherent articles at >10 000 pages/day; handling layout diversity and excluding non-article regions are the dominant engineering challenges. |
Applied deep learning, computer vision, & agentic AI
~2016-ongoing: centrepiece applied-ML research programme

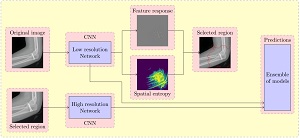
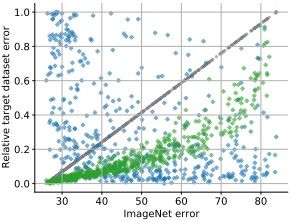
A distinctive contribution is the systematic study of the gap between benchmark-driven research and real-world deployment. The invited paper “Deep Learning in the Wild” (ANNPR’18) distils lessons from six production use cases. The companion book chapter “Beyond ImageNet” (Springer, 2019) generalises these into transferable principles. The MDPI AI paper on “Design Patterns for Resource-Constrained Automated Deep-Learning Methods” (2020) synthesises the methodological takeaways into reusable patterns. The Frontiers’22 paper closes the loop empirically, showing that ImageNet-optimal architectures fail to transfer across domains.
| Paper | Key finding / message |
|---|---|
| Tuggener et al., SDS’26 | Production NLP requires engineering beyond model accuracy: class imbalance, domain terminology, and distribution drift must be addressed to bridge the POC-to-production gap. |
| Sager et al., JAIR’26 | A comprehensive survey of AI agent architectures maps perception, memory, planning, and action across LLM-based and classical agents, identifying open challenges for autonomous systems. |
| Tuggener et al., Frontiers in Computer Science’25 | Artifical mental roation achieves efficient rotation invariance as a simple add-on to established CNN and transformer-based computer vision architectures, reducing the computational cost of equivariant architectures significantly. |
| Sager et al., CLEF’25 | A hybrid retrieval pipeline combining lexical precision, semantic generalization, and deep retrieval consistently outperforms individual methods for scientific-claim verification. |
| Tuggener et al., SDS’24b | Local LLM deployment on commodity hardware is feasible; quantisation is the dominant cost-reduction lever with acceptable quality trade-offs. |
| Meyer et al., SDS’24a | ScalaGrad provides statically typed automatic differentiation, catching shape and type errors at compile time rather than runtime, reducing DL debugging overhead. |
| Tuggener et al., Frontiers in Computer Science’22 | CNN architectures optimised on ImageNet do not reliably transfer across domains; architecture search must be domain-aware to achieve strong out-of-distribution performance. |
| Tuggener et al., MDPI AI’20 | Seven reusable design patterns cover the majority of resource-constrained AutoML scenarios and lead to top-5 results in international AutoML competitions. |
| Glüge et al., ANNPR’20 | Empirically testing face recognition DL networks shows demographic accuracy disparity is uncorrelated with model awareness of sensitive attributes — blinding is ineffective as a de-biasing strategy. |
| Amirian et al., TAILOR’20 | Trustworthy DL deployment requires explicit documentation of model genesis and interpretability; these are engineering requirements, not optional extras. |
| Amirian et al., ECML-PKDD’19 | Neural architectures transfer from image to video classification through temporal preprocessing and test-time ensembling; MobileNetV2 provides the best accuracy–efficiency trade-off. |
| Stadelmann et al., ADS ch. ‘Beyond ImageNet’ (2019) | Most industrial DL projects require domain-specific data curation, loss shaping, and calibration absent from canonical ImageNet training; they also rarely are just straightforward classifiers. |
| Tuggener et al., SDS’19 | A systematic taxonomy of AutoML design choices bridges the gap between academic benchmarks and industry requirements, guiding practical AutoML system design. |
| Stadelmann et al., ANNPR’18 | Six different case studies of fielded, innovative DL applications reveal design patterns like real DL deployment requiring wrapping core models in ensembles of auxiliary modules (quality assessment, anti-spoofing, calibration); benchmark accuracy is necessary but not sufficient. |
| Amirian et al., ANNPR’18 | Backpropagation-based feature maps detect adversarial attacks on CNNs, providing a lightweight defence mechanism against adversarial attacks. |
Medical image analysis
~2021-ongoing: growing interdisciplinary programme
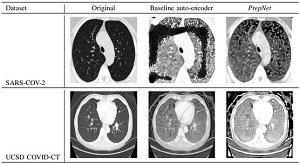
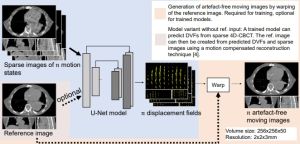
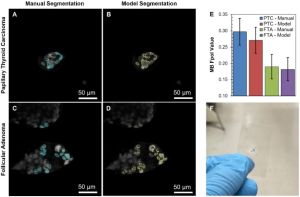
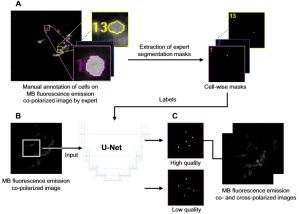
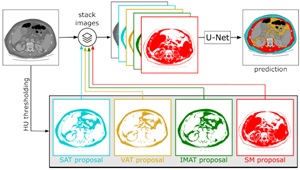
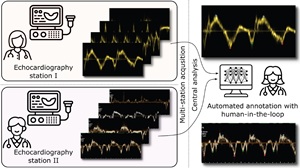
A growing body of work addresses clinical imaging, e.g.: (a) cross-domain generalisation: PrepNet homogenises heterogeneous CT scanners; (b) motion artefact correction in CBCT (MedPhys’23, top-viewed Wiley article); (c) cell segmentation for stain-free thyroid cancer diagnosis (Sci. Reports’24); (d) inductive bias design: unsupervised domain adaptation with a “domain sanity loss” detects vertebrae across scanner vendors; Hounsfield unit priors enable data-efficient CT segmentation within a single clinic (SDS’25b, Best Paper Award). The unifying theme is encoding domain knowledge as inductive biases to overcome data scarcity.
| Paper | Key finding / message |
|---|---|
| Ali et al., ISBI’26 | A vendor-agnostic DL pipeline for pulsed-wave tissue Doppler analysis decouples image acquisition from interpretation, enabling fleet-wide centralised cardiac diagnostics. |
| Meyer et al., SDS’25b | Ingesting medical know-how as inductiv bias into the model architecture enables data-efficient CT body-composition segmentation within a single clinic, achieving better accuracy with fewer than half the samples. |
| Jermain et al., Scientific Reports’24 | DL cell segmentation on rapid optical cytopathology images matches standard pathology accuracy for thyroid cancer, enabling real-time point-of-care diagnosis. |
| Jermain et al., BioMed’24 | Fluorescence-based rapid optical cytology combined with DL segmentation provides a fast, stain-free alternative to conventional histopathology for thyroid lesion triage. |
| Amirian et al., MedPhys’23 | Deep CNNs reduce motion artefacts in 4D-CBCT to clinically acceptable levels, cutting processing time from hours to seconds for image-guided radiotherapy. |
| Emberger et al., SDS’23b | DL on ICU biosensor streams can reduce continuous staff monitoring burden; reliable alert generation requires careful calibration to minimise false alarms. |
| Herzig et al., AAPM’22 | Simultaneous multi-phase DL deformable image registration of sparse 4D-CBCT achieves accurate respiratory-phase alignment, supporting adaptive radiotherapy workflows. |
| Sager et al., JImaging’22 | A ‘domain sanity loss’ achieves robust vertebra detection across scanner vendors without paired training data; ca. 10 in-house samples suffice as the domain anchor. |
| Amirian et al., CISP-BMEI’21 | PrepNet harmonises heterogeneous CT scanner outputs, enabling cross-domain COVID-19 diagnosis without retraining; preprocessing standardisation is the key enabling step. |
AI ethics & societal implications
~2021-ongoing: normative and empirical strand
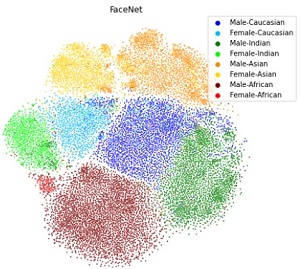


A distinct thread examines the ethical and societal dimensions of AI. The 2021 AI and Ethics paper on face recognition demonstrates empirically that blinding a model to sensitive attributes does not reduce bias, directly challenging a widely proposed de-biasing strategy. The 2023 AI and Ethics paper proposes a systematic work programme for the humanities to assess deep learning in its relationship to the human. The 2026 AI and Ethics paper establishes that the stochastic nature of ML training has direct safety implications for high-consequence deployments, and proposes co-learning for meaningful human control. The invited PMM’26 paper proposes an evidence-based framework for AI risk assessment in public policy, arguing against worldview-induced AI fears.
| Paper | Key finding / message |
|---|---|
| Stadelmann et al., uDay’26 | Establishing Pro-human AI as a design methodology for user-facing AI systems, including preliminary results from an implemented use case together with Alpine AI. |
| Stadelmann, T&TC’26 | A introduction to LLMs for theologians and other humanties scholars traces technical foundations to societal implications, carfully laying out the mental models of AI and argueing for a modest definition of AI as simulating intelligent behaviour. |
| Stadelmann, TENuK’26 | AI’s stochastic nature and human factors in complex socio-technical systems jointly determine safety; future-faced organisations in high-consequence areas must integrate both perspectives though co-learning labs. |
| Stadelmann et al., AI & Ethics’26 | ML’s inherent stochasticity must be explicitly accounted for in safety engineering; co-learning provides a principled framework for meaningful human oversight of high-consequence systems. |
| Stadelmann, PMM’25 | AI risk assessments in public policy are primarily driven by worldviews rather than evidence; an evidence-based technical framework tied to specific ML properties is needed. |
| Stadelmann, GRW’25 | Conflicting AI narratives reflect differing worldviews; a technically grounded guide helps decision-makers navigate them and form independent, evidence-based judgments. |
| Stadelmann, KIW’25 | A German-language guide argues for confident AI engagement grounded in technical understanding, navigating narratives between uncritical enthusiasm and unfounded fear. |
| Segessenmann et al., AI & Ethics’23 | A structured humanities-informed work programme for critically assessing DL spans epistemology, ethics, and societal impact, providing actionable research questions for non-technical disciplines. |
| Stadelmann, Bürgenstock’23 | AI is a strategic opportunity for universities of applied sciences; the applied mandate becomes a competitive advantage in the era of transformative technology. |
| Wehrli et al., AI & Ethics’21 | Model awareness of sensitive features and demographic accuracy disparity are empirically uncorrelated; blinding face-recognition models to protected attributes is not a valid de-biasing technique. |
| Glüge et al., ANNPR’20 | Face recognition systems show persistent demographic accuracy disparities despite overall high performance; standard benchmarks mask these disparities and should not be used as fairness proxies. |
| Stadelmann, FCW’19 | ML-driven automation is restructuring how money is earned; organisations treating ML as augmenting judgment rather than replacing it will benefit most from the transition. |
Theoretical foundations of intelligence
~2018-ongoing: theoretical / foundational strand




In collaboration with Christoph von der Malsburg (Frankfurt) and Benjamin Grewe (ETH Zurich), a theoretical programme investigates why natural intelligence is so data-efficient compared to current AI. The central argument in “A Theory of Natural Intelligence” (arXiv’22) is that both brain and natural environment are highly structured and that this mutual structural regularity acts as the key inductive bias enabling rapid, generalising learning via self-organised “net fragments.” The Neural Computation’26 paper instantiates the cooperative network architecture as a concrete instance of this theory, hinting at how a next level of AI could be build. At the same time, our ICML’25 paper showed that Transformer self-attention develops symmetry and directionality structures during training, informing deeper understanding of current mainstream ML methods. Already in 2018, we developed a method to learn clustering algorithm, and solved in-plane rotation invariance for practical purpuses in 2025..
| Paper | Key finding / message |
|---|---|
| Sager et al., Neural Computation’26 | The cooperative network architecture instantiates net-fragment theory, learning structured compositional representations with strong few-shot generalisation from limited data. |
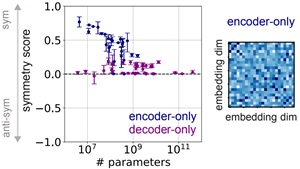
| Saponati, Sager et al., ICML’25 | Self-attention in Transformers develops symmetry and directionality structures during training; this theoretical grounding explains why symmetry-based initialisation tricks accelerate learning. |
| Tuggener et al., Frontiers in Computer Science’25 | Artifical mental roation achieves efficient rotation invariance as a simple add-on to established CNN and transformer-based computer vision architectures, reducing the computational cost of equivariant architectures significantly. |
| von der Malsburg, Stadelmann, Grewe, KogWis’22 | Cognition arises from structural regularity shared between brain and environment; perception is active hypothesis testing, not passive pattern matching. |
| von der Malsburg, Stadelmann, Grewe, arXiv’22 | Brain and natural environment are mutually highly structured; self-organised ‘net fragments’ serve as the structural inductive bias enabling data-efficient natural learning: a blueprint for next-generation AI. |
| Roost et al., AVHRC’20 | Active-perception RL (i.e., coupling image acquisition and classification in one model) learns more informative scene representations than episodic classification paradigms. |
| Meier et al., ANNPR’18 | An end-to-end neural architecture learns probabilistic clustering “algorithms” in a single forward pass that are able to jointly estimating cluster count and assignments. |
Graph neural networks for pattern recognition
~2022-2026: methodical deep dive
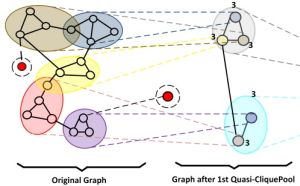
A self-contained thread, developed in collaboration with Marcello Pelillo (Venice), investigates graph-based deep learning, particularly the design of expressive yet computationally efficient graph pooling operators for graph classification. Key contributions include Quasi-CliquePool (SAC’23), Hierarchical Glocal Attention Pooling (PRL’24), Multi-View Pooling via Dominant Sets (Pattern Recognition’26), and Community-Hop for node classification (S+SSPR’24). These methods consistently outperform prior pooling approaches while maintaining interpretability through their graph-theoretic foundations.
| Paper | Key finding / message |
|---|---|
| Ali et al., NNICE’26 | Topology-aware graph augmentation enhances GNN robustness and generalisation for graph classification without introducing additional learnable parameters. |
| Ali et al., Pattern Recognition’25 | Treating graph pooling as dominant-set clustering provides a principled, edge-weight-aware, parameter-efficient alternative to learned pooling operators. |
| Ali et al., S+SSPR’24 | Community-Hop leverages graph community structure as a message-passing inductive bias, achieving strong node-classification performance especially on heterophilic graphs. |
| Ali et al., Pattern Recognition Letters’24 | Combining global topological structure with local neighbourhood attention in a hierarchical pooling scheme achieves state-of-the-art graph classification across standard benchmarks. |
| Ali et al., ACM SAC’23 | Quasi-CliquePool uses clique-relaxation clustering to form hierarchical graph summaries, matching or surpassing prior pooling methods with a transparent graph-theoretic foundation. |
| Hibraj et al., ICPR’18 | Dominant-Sets clustering applied to speaker-embedding graphs achieves competitive diarisation without prior knowledge of speaker count, bridging GNN and audio research. |
Speaker recognition & audio representation learning
~2004-ongoing: formative line from PhD to continued breakthroughs with deep learning

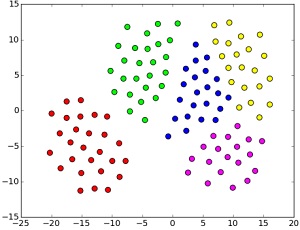
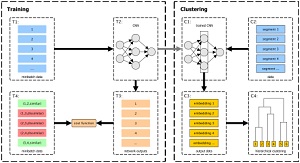
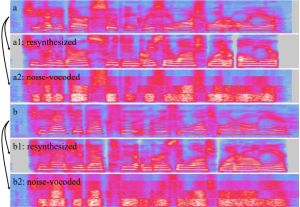
The earliest sustained research thread centres on automatic speaker recognition. Thilo Stadelmann’s PhD thesis (Marburg, 2010) introduced the Dimension-Decoupled Gaussian Mixture Model for coping with very short speech segments and established that improved recognition hinges at exploitng temporal cues in a voice. Later work introduced deep learning to the field: CNNs applied directly to spectrograms (MLSP’16, >100 citations) proved competitive for both speaker identification and clustering. Subsequent work attempted to use RNNs to capture supra-segmental voice characteristics (ANNPR’18b) and metric-learning embeddings for measuring voice similarity (MLSP’17). A 2024 Pattern Recognition Letters paper delivers a sobering counter-result: deep networks for speaker recognition do not yet learn supra-segmental temporal features, raising open questions about what these models actually learn.
| Paper | Key finding / message |
|---|---|
| Neururer et al., Pattern Recognition Letters’24 | DNNs for automatic speaker recognition learn spectral but not supra-segmental temporal features, even on tasks that in principle require them: a fundamental open challenge for the field. |
| Stadelmann et al., ANNPR’18 | RNNs processing spectrograms across long speech segments appear to capture supra-segmental prosodic features, improving voice clustering over frame-level CNN approaches. |
| Hibraj et al., ICPR’18 | Dominant-Sets graph clustering of speaker embeddings achieves accurate diarisation without fixing the number of speakers in advance. |
| Lukic et al., MLSP’17 | Metric-learning objectives optimised directly for clustering quality produce speaker embeddings that outperform classification-trained embeddings for diarisation. |
| Lukic et al., MLSP’16 | CNNs trained on spectrograms achieve state-of-the-art speaker identification and clustering without hand-crafted features; one of the earliest such demonstrations, predating x-vectors. |
| Stadelmann et al., VDI-FASiS’12 | Real-time audio classification enables a meta-driver-assistance system to detect driver distraction acoustically, demonstrating a safety-relevant application of audio event recognition. |
| Beecks et al., ICME’10 | Exploring visualizations of speaker models graphically unlocks very helpful insights for the developer. |
| Stadelmann & Freisleben, ICPR’10a | Dimension-decoupled GMMs safe most of the parameters normally used for voice modeling, yielding significantly improved speaker identification from very short utterances. |
| Stadelmann et al., ICPR’10b | A critical review of speech processing algorithm design advocates for a principled approach that keeps the human in the loop by means of their intuitive perceptual capabilities. |
| Stadelmann & Freisleben, TR’10 | Cepstral features are theoretically and practically incompatible with the MixMax speech/noise model; published results that report contrarian results are based on a bug in the code. |
| Stadelmann, PhD thesis (2010) | The thesis combines our work on voice modeling methods under complex acoustic conditions as encountered in multimedia indexing. |
| Stadelmann & Freisleben, ACMMM’09 | Established that temporal features (as in human speaker recognition) are key to unlock an order of magnitude lower error rates in complex speaker recognition scenarios. |
| Stadelmann et al., CISP’09 | WebVoice provides an interactive web-based toolkit for visualising and probing speech processing algorithms from a perceptual perspective, supporting reproducible research. |
| Stadelmann & Freisleben, ICASSP’06 | Earth Mover’s Distance with MixMax speaker models enables fast, robust speaker clustering on degraded real-world recordings without prior knowledge of the number of speakers. |
Data Science as a scientific discipline
~2013-2022: conceptual / disciplinary foundation work



Running parallel to empirical research is a sustained effort to define and legitimise data science as a discipline in its own right, based on the early involvement of the group in founding the first continental Europan data science lab and the corresponding conference series. The early papers (ECSS’13, HMD’14, HMD’16) characterised the emerging role of the “data scientist.” The Springer edited volume Applied Data Science (2019, >123 000 accesses) became a widely-read practitioner reference. The 2022 Archives of Data Science paper “Data Centrism and the Core of Data Science” provides the most theoretically developed argument: that data centrism, treating data as the central object of study rather than a means to an end, is the overarching principle distinguishing data science from statistics, ML, and data management.
| Paper | Key finding / message |
|---|---|
| Stadelmann et al., AoDSA’22 | Data centrism (i.e., treating data as the central subject of study rather than a resource) is the unique disciplinary core distinguishing data science from statistics, ML, and data management. |
| Schilling et al., AoDSA’22 | A symposium synthesis identifies four pillars of data science’s scientific core: foundations, methods, systems, and applications, each requiring inquiry beyond contributing disciplines. |
| Stadelmann et al., EducSci’21 | The AI-Atlas didactic framework structures AI/ML teaching for on-site, online, and hybrid delivery; modular design enables transfer across institutions with diverse resource levels. |
| Stadelmann et al., ADS ch. ‘Beyond ImageNet’ (2019) | Industrial DL projects consistently require domain-specific data engineering steps absent from ImageNet training; ‘necessity is the mother of invention’ is the central lesson. |
| Braschler et al., ADS ch. ‘Data Science’ (2019) | Data science is defined as a unique blend of principles and methods from analytics, technology, and domain expertise; no single contributing discipline provides this combination. |
| Stadelmann et al., ADS ch. ‘Data Scientists’ (2019) | The data scientist role requires a T-shaped profile spanning analytics, technology, communication, and domain knowledge; curricula must address all four components. |
| Stockinger et al., ADS ch. ‘Lessons Learned’ (2019) | Applied data science is always data-driven, not method-driven; case studies show ‘necessity is the mother of invention’ consistently explains method choice. |
| Hollenstein et al., ADS ch. ‘Complexity’ (2019) | Synthetic simulation data provides a viable fallback when real data is unavailable mid-project; bridging simulation and real-data distributions is the key challenge. |
| Meierhofer et al., ADS ch. ‘Data Products’ (2019) | Data products (i.e., reusable, deployable artefacts encapsulating data science results) provide a systematic route from analytical insight to repeatable business value. |
| Stockinger et al., HMD’16 | The data scientist profession requires combined analytical, technical, and communication skills that no single prior discipline covers; educational programmes must be purpose-built. |
| Stadelmann et al., ERCIM News’15 | Automatic data curation for open data (i.e, detecting inconsistencies, inferring missing values, and enforcing schema constraints) is identified as a scalable alternative to purely manual cleaning. |
| Dessimoz, Koehler, Stadelmann, AI Magazine’15 | A survey of Swiss AI research identifies distinctive strengths in applied and foundational areas; interdisciplinary industry-academia collaboration is the defining characteristic. |
| Stockinger & Stadelmann, HMD’14 | Data science integrates computer science, statistics, and domain expertise; early institutional investment in dedicated labs and curricula is essential for establishing the field. |
| Stadelmann et al., ECSS’13 | Data science was identified early as a rapidly emerging field combining analytics, technology, and communication; none of the contributing disciplines provides this combination alone. |
Multimedia analysis
~2004-2010: work on video content analysis and retrieval
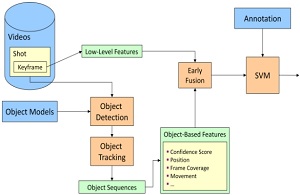

We started our research work with applications in video content analysis and multimedia retrieval: annual participation in the TREC Video Retrieval Evaluation (TRECVid) benchmark yielded contributions to shot boundary detection (TRECVid’05, TRECVid’06, TRECVid’07), camera motion estimation, and high-level semantic feature extraction from broadcast video (TRECVid’08, TRECVid’09). These methods were integrated into the Videana toolkit (DTiMS’07), which made automated film content analysis accessible to humanities scholars, and applied to psychological research on media violence (CIVR’07). The respective methods (including our sound analysis and speaker diarization algorithms) got integrated into distributed media infrastructure: a service-oriented grid architecture (IJWGS’09, GeNeMe’09) and accompanying tooling for web service generation (ICWS’09) and legacy-code wrapping (ERPAS’09) enabled large-scale multimedia analysis pipelines to run on shared grid compute resources (the predecessor paradigm of cloud computing).
| Paper | Key finding / message |
|---|---|
| Mühling et al., TRECVid’09 | SVM classifiers on visual descriptors achieve competitive high-level concept detection in broadcast video; colour and texture features are the most informative cues. |
| Heinzl et al., IJWGS’09 | A service-oriented architecture integrating analysis, storage, and presentation scales to large multimedia archives across distributed sites; data transfer is the dominant performance bottleneck. |
| Heinzl et al., ICWS’09 | Automatic WSDL-based client generation and binary transfer protocols substantially reduce web service integration effort for multimedia workloads. |
| Seiler et al., GeNeMe’09 | A grid infrastructure for humanities film analysis combines automated content analysis tools with the workflow requirements of film scholars, enabling quantitative study of large film collections. |
| Juhnke et al., ERPAS’09 | The LCDL framework wraps existing scientific code as web services without source modification, enabling legacy analysis tools to participate in distributed multimedia pipelines. |
| Mühling et al., TRECVid’08 | Multi-class SVM ensembles for high-level feature extraction in broadcast news; cross-year transfer of trained concept detectors degrades significantly, motivating continuous retraining. |
| Mühling et al., TRECVid’07 | Combined shot boundary detection and semantic concept extraction in a single pipeline; spatial and temporal visual features complement each other for robust scene classification. |
| Ewerth et al., DTiMS’07 Videana | The Videana toolkit integrates shot detection, speaker recognition, face detection, and concept tagging into a single interface, making quantitative film analysis accessible to humanities scholars without programming. |
| Mühling et al., CIVR’07 | Automated semantic video analysis applied to game-violence psychology research enables reproducible, large-scale content coding at a scale impossible by manual annotation. |
| Ewerth et al., TRECVid’06 | Shot boundary detection with visual change metrics and rushes task processing; clean temporal segmentation is a prerequisite for all higher-level video analysis tasks. |
| Ewerth et al., TRECVid’05 | Baseline shot boundary detection and camera motion estimation on standardised benchmarks; foundational infrastructure for the group’s subsequent video content analysis work. |
Reinforcement learning & Physical AI
~2020-ongoing: sequential decision-making and real-world acting for robotics and other cyber-physical systems
A thread running through several applied projects concerns reinforcement learning (RL) at the boundary between software and the physical world. Roost et al. (SDS’20) trains multi-agent RL to reschedule delayed trains in real time, exposing sample efficiency and inter-agent communication as the key bottlenecks for real rail deployment. Roost et al. (AVHRC’20) combines RL with active perception, coupling image acquisition and classification in a feedback loop to yield richer scene representations than passive episodic classification. Bolt et al. (ANNPR’24) applies RL to building energy management, showing that a simulation-trained mixed-agent PPO controller substantially outperforms rule-based HVAC controllers and avoids the costly modelling assumptions required by Model Predictive Control. Bolck et al. (Frontiers Robotics & AI’26) address the upstream problem: before RL-powered AI can be deployed in robotics like unmanned aerial vehicles, dedicated testing infrastructure is needed; the LINA infrastructure provides the systematic validation pipelines required for AI certification in safety-critical autonomous systems.
| Paper | Key finding / message |
|---|---|
| Bolck et al., Frontiers Robotics & AI’26 | Safety certification of AI in UAVs demands dedicated testing infrastructure; the LINA infrastructure provides systematic validation pipelines that address AI-specific certification challenges absent from traditional avionics processes. |
| Bolt et al., ANNPR’24 | Simulation-trained RL substantially outperforms rule-based HVAC controllers and avoids MPC modelling costs; a mixed-agent PPO approach accelerates convergence and transfers to real building operation. |
| Roost et al., SDS’20 | Multi-agent RL outperforms rule-based schedulers for real-time train rescheduling; sample efficiency and learned inter-agent communication are the dominant bottlenecks for deployment in live rail networks. |
| Roost et al., AVHRC’20 | Active-perception RL (i.e., coupling image acquisition and classification in a closed feedback loop) produces more informative scene representations than standard episodic classification, motivating joint optimisation of sensing and inference. |
Examples of translation into practice
The table below maps concrete, practitioner-relevant examples from across the research portfolio to their domain, method, and key practical takeaways.
| Application | Domain | What was done | Practical takeaway | |
|---|---|---|---|---|
|
Echocardiography tissue velocity measurement | Cardiology | Automated, vendor-agnostic DL pipeline measures myocardial tissue velocities in echocardiography scans. (ISBI’26) | Automating a clinically routine but tedious measurement step removes vendor lock-in and enables consistent, reproducible cardiac diagnostics. |
|
AI testing infrastructure for UAVs | Aviation / robotics | LINA testing infrastructure enables systematic AI validation in unmanned aerial vehicles, addressing certification challenges. (Frontiers in Robotics and AI’26) | Safety-critical AI needs dedicated testing infrastructure before deployment; certification pipelines for autonomous systems must be part of the engineering process. |
|
AI risk assessment for public policy | Governance / regulation | Evidence-based framework mapping technical ML properties (stochasticity, distributional shift) to policy-relevant risk categories. (PMM’26; AI&Ethics’26) | Regulators need technically grounded criteria; the stochastic nature of ML training must be explicitly acknowledged in safety cases and hypothetical risk not overestimated. |
|
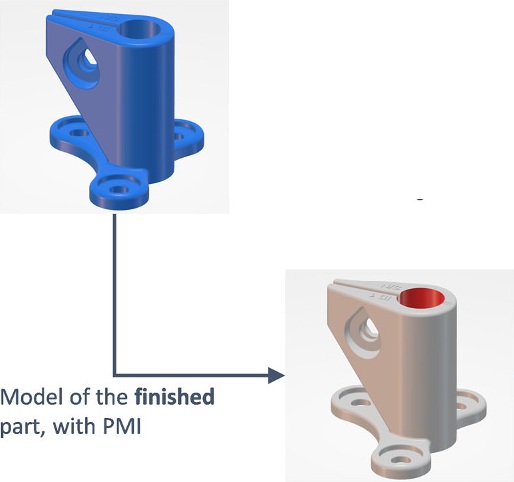
3D metal printing cost optimisation | Additive manufacturing | Merged GD&T information back from 2D engineering drawings into the 3D master model for optimised cost calculation in parts manufacturing (BHM’25) | Data-driven cost modelling directly integrates with CAD design workflows, enabling earlier economic feasibility checks for additive manufacturing. |
|
Human-AI teaming in safety-critical infrastructure | Operations / safety | Systematic analysis of human-AI collaboration in safety-critical systems, introducing co-learning as a development paradigm. (iScience’25) | Purely autonomous AI is inappropriate in regulated contexts; trust calibration, explainability, and explicit workload allocation are design requirements, not afterthoughts. |
|
Injection moulding process monitoring & control | Manufacturing / plastics | Representation learning for automated process monitoring (SDS’24c); world-model-based learning for closed-loop industrial process control from limited real data (SDS’25a). | Data-centric anomaly detection and world models together enable process control with very limited labelled data, showing a practical path to AI adoption in traditional manufacturing. |
|
Thyroid cancer cytology | Pathology / oncology | Cell segmentation on rapid optical cytopathology images (no sending to a lab required) enables real-time diagnosis at the primary point of care. (Sci. Reports’24) | Rapid optical biopsy becomes clinically feasible; DL cell segmentation matches standard pathology accuracy. |
|
Geothermal reservoir modelling | Energy / geology | Ensemble deep learning quantifies uncertainty in geothermal reservoir properties from sparse borehole data. (Geothermics’24) | Probabilistic DL models provide actionable uncertainty bounds for drilling decisions with very limited training data. |
|
Building energy optimisation | Energy / smart buildings | RL agent controls HVAC to minimise energy consumption while satisfying occupant comfort constraints, trained in simulation. (ANNPR’24) | Simulation-to-real transfer is feasible with proper domain randomisation; RL substantially outperforms rule-based controllers. |
|
Optical music recognition on real historical scores | Cultural heritage / publishing | Deployed DL-based OMR on digitised manuscripts with domain adaptation and automated confidence scoring. (TISMIR’24) | Production OMR requires domain adaptation; benchmark accuracy on rendered scores does not predict real-world performance. |
 |
Private LLM deployment benchmark | Enterprise IT / data privacy | Survey and benchmark of efficient on-premise LLM methods, covering quantisation, LoRA, and knowledge distillation. (SDS’24b, Honourable Mention Best Paper) | Organisations can deploy capable LLMs on local hardware at acceptable quality loss; quantisation is the dominant cost-reduction lever. |
|
Radiotherapy CBCT artefact correction | Medical physics | Deep CNNs reduce motion artefacts in cone-beam CT scans, improving image quality for treatment planning. (MedPhys’23, Top-Viewed) | DL replaces iterative reconstruction, cutting processing from hours to seconds at equivalent image quality. |
 |
Solar cell characterisation | Materials / clean energy | Deep ensemble inverse models estimate physical material parameters of organic solar cells from electroluminescence images. (APLML’23; SDS’21b, Best Paper) | Ensembles trained on synthetic simulation data reliably invert physical imaging models; uncertainty quantification is essential. |
|
Mathematical formula recognition | Publishing / accessibility | Data-centric approach with the FormulaNet benchmark achieves reliable printed formula detection and recognition. (Access’22; Access’24) | Data quality and annotation consistency matter more than model architecture; the bottleneck is the training set, not the network. |
|
Vertebra detection across scanner vendors | Radiology | Unsupervised domain adaptation with a “domain sanity loss” detects vertebrae across heterogeneous CT scanners without paired training data. (J. Imaging’22) | Vendor-agnostic medical AI is achievable without costly re-annotation; the domain sanity loss provides a lightweight supervision signal, needing only a handful of internal samples. |
|
Bias testing in face recognition | Ethics / HR / law enforcement | Empirically tested whether “blinding” a face recognition model to gender/race reduces accuracy disparity across demographic groups. (AI&Ethics’21) | Blinding does not reduce bias. Organisations cannot rely on simple attribute removal as a fairness guarantee. |
 |
AI/ML teaching concept (ATLAS) | Higher education | The AI Atlas didactic framework structures AI/ML teaching for on-site, online, and hybrid delivery, empirically validated. (EducSci’21) | The ATLAS framework is directly transferable across institutions, offers sample syllabi and exercises, and provides educational design scaffolding. |
|
Train rescheduling | Rail / logistics | Multi-agent RL agents reschedule delayed trains, collaborating via communication to restore timetable adherence. (SDS’20, Best Poster) | RL outperforms rule-based schedulers; sample efficiency and learned communication are the bottlenecks for real deployment. |
|
Face-ID verification product | Identity & security | Full production pipeline: orientation detection, image quality assessment, anti-spoofing (3-method ensemble), face matching, user guidance. (ANNPR’18d) | A single ML model is often not enough in production; wrapping in auxiliary quality and security modules is mandatory. |
|
Newspaper article segmentation | Media / publishing | FCNNs segment printed newspaper pages into articles at >10’000 pages/day for a media monitoring company. (ICDAR’17) | Excluding non-article regions and handling layout diversity are the dominant engineering challenges, not the core model. |
Main scientific contributions
The following contributions represent the group’s most coherent and strong scientific claims with a clear arc, a body of evidence, and an open trajectory.
Neural speaker recognition and diarization
~2004-ongoing: temporal features as key, with ongoing relevance as a methodological platform
Starting from first principles in signal processing and statistical modelling, this line of work built a comprehensive account of how to identify and cluster speakers automatically from audio (the task known as speaker diarization). The early contributions (ICASSP’06) introduced fast and robust speaker clustering using Earth Mover’s Distance and MixMax models, operating on real-world degraded recordings without prior knowledge of the number of speakers. The doctoral dissertation (2010) provided the most complete treatment of voice modelling methods for speaker recognition of its time, systematically comparing generative and discriminative approaches across diverse corpora. It established the main finding that for speaker recognition accuracy under adverse conditions (small and noisy segments) that is on par with humans, temporal features need to be taken into account (next to spectral features).
The line was continued by deep learning, based on the hope that treating spectrograms as images would naturally allow leared features to extend into both the temporal ans spectral dimension: MLSP’16 demonstrated that convolutional networks trained on spectrograms could learn speaker-discriminative embeddings that cluster across unseen recordings without retraining: one of the early demonstrations of this paradigm before x-vectors became standard practice. The follow-up MLSP’17 refined the approach through metric learning objectives directly optimised for clustering quality. The 2024 PRL article shows empirically that this search for methodology that adequately exploits temporal features is not over, yet. Together, this body of work documents a full methodological cycle from classical statistical approaches to neural representations, establishing the group as a European reference point in audio-based biometric intelligence.
Dense small-object detection: DeepScores and the Deep Watershed Detector
~2017-2025: OMR transformed, with DeepScores as an ongoing community resource
This is the group’s strongest claim to a core computer vision contribution. Standard object detectors like YOLO, SSD, and Faster R-CNN share a structural failure mode when applied to images containing large numbers of very small, densely packed objects: grid-based anchor mechanisms impose spatial constraints that prevent detecting multiple co-located objects regardless of training data or hyperparameter tuning. DeepScores (ICPR’18), with 80 million labelled objects across 300,000 high-resolution images of music notation, makes this failure mode precisely measurable. At several orders of magnitude larger in object count than PASCAL VOC or MS-COCO, it poses the dense small-object detection problem to the broader computer vision community rather than to optical music recognition alone.
The Deep Watershed Detector (ISMIR’18) addresses this structurally: instead of bounding-box regression from a spatial grid, it predicts a dense energy map where object centres appear as local peaks extracted by the watershed transform. This makes it conceptually an anchor-free dense detector, contemporaneous with CornerNet (ECCV’18) but derived from different mathematical foundations that provide a clean topological justification for handling crowded scenes. A model trained on synthetically rendered scores generalised directly to handwritten notation (MUSCIMA++) without retraining, a strong out-of-distribution result. Subsequent work (TISMIR’24) extended and validated the approach on real-world scores and real-world applications, closing the translational research loop.
Applied deep learning: from benchmarks to production
~2018-ongoing: systematic methodology for closing the benchmark-to-deployment gap
A sustained and distinctive contribution addresses a problem that most ML research sidesteps: the systematic mismatch between benchmark conditions and real-world deployment. The invited position paper “Deep Learning in the Wild” (ANNPR’18) distilled lessons from six production deployments (face verification, media monitoring, industrial quality control, music scanning, game playing, and automated machine learning) into a taxonomy of failure modes that predates much of the later “reproducibility crisis” literature in ML. Its central claim: a core DL model alone rarely suffices; reliable production systems require a surrounding ensemble of quality-assessment, uncertainty-quantification, and domain-adaptation modules to make them sample-efficient. The complementary chapter “Beyond ImageNet” (Springer Applied Data Science book, 2019) generalises these observations into transferable design principles for practitioners who cannot assume ImageNet-like data abundance or curation.
The methodological arc culminates in two convergent results. The MDPI AI paper “Design Patterns for Resource-Constrained Automated Deep-Learning Methods” (2020) synthesises the recurring architectural decisions across AutoML deployments into seven reusable patterns: a vocabulary that practitioners can apply without rediscovering the same engineering lessons from scratch. The Frontiers in Computer Science paper (2022) then closes the empirical loop: systematic experiments demonstrate that CNN architectures optimised on ImageNet fail to reliably transfer across domains, making the case for domain-aware architecture search. Together, this body of work constitutes a principled engineering science of deep learning deployment; not a critique of DL, but a programme for making DL efficient and robust in contexts it was not designed for.
Data science as a scientific discipline
~2013-2022: disciplinary foundations and the data-centrism argument
Running parallel to the empirical research record and influenced by leading the organizational build-up of the data science ecosystem in Switzerland (spear-heading the first academic unit in continental Europe, the first conference series, and a national association for academics and professionals) is a sustained effort to answer a question that most ML groups leave implicit: what is data science, and what epistemic status do its results have? The early position papers (ECSS’13; HMD’14; HMD’16) characterised the emerging data scientist role as requiring a combination of analytical, technological, entrepreneurial, and communicative competencies that no existing discipline provides intact, an argument against treating data science as merely applied statistics or software engineering. The Springer edited volume Applied Data Science (2019, >123 000 chapter accesses) translated this argument into a practitioner reference structured around the principle that data science is always data-driven, not method-driven.
The theoretical culmination is the Archives of Data Science paper “Data Centrism and the Core of Data Science” (AoDSA’22). Its central argument is that data centrism (treating data as the primary object of scientific study rather than as a resource from which models are extracted) is the unique disciplinary commitment that distinguishes data science from statistics, machine learning, and data management. Where statistics asks “what does the data tell us about the world?”, data centrism asks “what is the structure of this data, and what data would allow us to answer our question?” The implication is direct: data science should evaluate its own contributions primarily by the datasets it produces, curates, and analyses, not only by model accuracy on fixed benchmarks. This reframes the reproducibility discussion and provides a philosophically grounded rationale for why dataset creation and work on novel use cases counts as first-class scientific work.
From algorithmic research to societal questions
~2018-ongoing: increasingly the intellectual orientation based on the algorithmic expertise
The group has systematically traced what happens when machine learning results exit the research lab and encounter real human contexts, producing original scientific arguments at each stage of that transition. The invited position paper Deep Learning in the Wild (ANNPR’18) opened this line by cataloguing the gap between benchmark conditions and deployment realities, providing a taxonomy of failure modes that predates much of the later “reproducibility crisis” literature in ML. These were translated for non-technical audiences in a 2019 invited chapter that aged quite well with respect to its recommendations concerning the following 5 years.
On the applied side, the AI and Ethics (2021) bias study showed quantitatively that demographic awareness in face recognition design does not translate to reduced bias at deployment. Assessing Deep Learning (AI and Ethics’23) proposed a humanities-grounded framework for evaluating AI systems beyond technical metrics. Most recently, PMM’26 and AI and Ethics’26 formalised how intrinsic ML properties (stochasticity of training, distributional shift) map to policy-relevant risk categories, giving regulators technically grounded criteria that go beyond checklist compliance. In another translatory effort, these have been made accessible to general public audiences in form of a TEDx talk.
Ideas we’d love to work on more in the future
Project opportunities abound, and we keep being involved in several activities in medical imaging, multimedia analysis, robotics / physical AI, speaker diarization (to name a few). However, the following 5 research directions that emerged from our work appear to us as “golden”: ideas that have not yet reached full maturity, yet their potential impact can already now be assessed as huge. Hence, we are actively seeking ways to inquire more in these directions and seek respective collaborations, notwithstanding our general openness to interesting use cases and challenges. The order is from algorithmic to societal, the links point to previous publications giving more insight. If you are interested in those (and see an opportunity also for funding respective work), please get in touch.
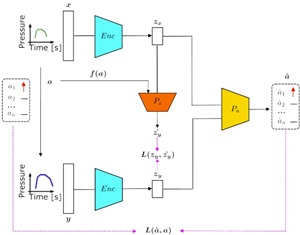
Next-level, neuroscience-informed AI based on world models for higher sample efficiency and robust understanding of cause and effect of actions, e.g. for robot control
While the current AI paradigm of deep learning has led to very useful practical applications, it is fundamentally limited in many important ways that prevent any “next level” of capabilites beyond incremental improvements of the (again: extremely useful) status quo: For example, hallucinations in LLMs and VLAs instead of a robust understanding of the effect of certain actions are a direct result of probabilstic machine learning; lack of continual learning and low sample efficiency are a result of training with backpropagation (which proceeds in tiny steps and spreads each learnt concept over the whole network). Instead, biological learning systems use local learning rules to implement the principle of self-organization, which we have prototypically implemented in the Cooperative Network Architecture (CNA).
We want to extend the Cooperative Network Architecture to become a competitive AI development paradigm for challenges like long-horizon robotic action planning in world models, and scale it to make efficient use of modern compute architectures for applications in Physical AI.
Towards document foundation models based on an understanding of document recognition as image-to-record transcription
Many document types use intrinsic, convention-driven structures that serve to encode precise and structured information, such as the conventions governing engineering drawings. However, many state-of-the-art approaches treat document recognition as a mere computer vision problem, neglecting these underlying document-type-specific structural properties, making them dependent on sub-optimal heuristic post-processing and rendering many less frequent or more complicated document types inaccessible to modern document recognition. We have suggested a novel perspective that frames document recognition as a transcription task from a document to a record. This implies a natural grouping of documents based on the intrinsic structure inherent in their transcription, where related document types can be treated (and learned) similarly.
We want to scale this approach to build document foundation models with a unified design for all dcoument types beyond OCR, OMR and other realtively simple, sequential document structures, useful as practical rubrics for end-to-end semantic document understanding.
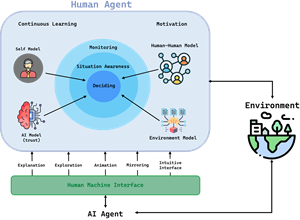
Co-learning as a framework for human-AI teaming in high-consequence environments
Because of the probabilistic nature of machine learning systems and the high functional requirements in high-consequence application scenarios, the typical mode of operation is to build human-AI teams, with the final responsibility with the human. But human oversight alone is not enough: psychological research has shown that humans need to have meaningful agency in any collaboration, otherwise they cannot help but become bored, reverting to mere mechanical approval without exercising supervision. A remedy is offered by the concept of co-learning developed in our AI4REALNET European research project for human-AI collaboration in the high-consequence scenario of operating critical network infrastructures. Co-learning maintains a setup in which with every interaction both the human and the machine learn from each other via bidirectional information flow: Not only do the humans provide training feedback to a continually learning ML system, but the AI system at the same time provides explainable insights to the human that help them understand and scrutinize decisions better. This happens within a long-term, iterative process of co-adaptation through interaction that leads to co-learning.
We want to advance co-learning systems and establish what we call co-learning labs, specifically outfitted training facilities or “gyms” in which humans and their AI systems can learn to support and complement each others’s strengths and weaknesses.
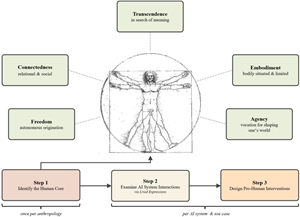
Pro-human AI design as a methodology to build AI systems specifically with the individual human's flourishing in mind (instead of accidentally eroding the human's core)
Artificial Intelligence systems are reshaping how we work, communicate, decide, and relate to one another. While most AI design focuses on efficiency and capability, a critical question has gone largely unanswered: how can AI systems be built in ways that preserve (and ideally strengthen) the constitutive characteristics of being human? We call this challenge pro-human AI design, and we call the set of those characteristics the Human Core. We have worked on a three-step methodology for implementing pro-human AI design, and instantiate it protptypically based on a concrete anthropological stance and a practical use case: (1) Identify the constitutive characteristics of the Human Core; (2) examine how a given AI system in a given use case interacts with these characteristics; (3) develop targeted technical interventions to minimize negative effects and support human flourishing in that context.
We want, in a next step is to thoroughly advance and empirically test this methodology, and develop a HUMANCORE benchmark for evaluating the pro-human quality of AI systems at scale in interdisciplinary collaboration with empirical psychologosits and other disciplines.
Scenario development for positive visions for our societal future with AI
The dominant public narrative surrounding artificial intelligence is overwhelmingly negative: extinction risks, mass unemployment, surveillance, manipulation. This narrative is not merely an intellectual curiosity; it shapes policy, investment, education, career choice, mental health, and individual behaviour. Yet it rests on a narrow slice of technically plausible futures: Vastly more scenarios are thinkable, many of them viable, even probable, yet we can only create what we can imagine (Lucille Clifton).
We want to addresses this gap directly with a constructivist approach in scenario development workshops to publish hopeful alternative scenarios, elaborated in co-creation processes with diverse experts and facilitatet by experienced media production teams.
