
Science, applied. Die wissenschaftliche Methode im Kern des Produktentwicklungsprozesses
This post represents my contribution to the best teaching award competition of my university in 2017; it was awarded a final round nomination (best 10).
Abstract
Jede Institution muss sich von Zeit zu Zeit fragen, warum sie die Dinge so macht, wie sie sie macht. Eine Bildungseinrichtung ist keine Ausnahme. Warum legen wir Wert auf Wissenschaftlichkeit, wenn wir doch für die Praxis ausbilden wollen? Dieses Lehrkonzept möchte die folgende Antwort beliebt machen:
“Weil das Anwenden der wissenschaftlichen Methode im Ingenieurskontext eine extrem gute Idee ist – sie führt deterministisch zu guten, praxistauglichen Lösungen beim Entwickeln neuer Produkte und Dienstleistungen”.
Daraus ergeben sich Folgefragen: Wie bringen wir unseren Studierenden mit Angst vor dem sprichwörtlichen Elfenbeinturm diese so relevante Wissenschaftlichkeit näher? Wie schlagen wir die Brücke von unserer Forschung zur Lebenswirklichkeit junger Menschen, die zukünftig nur einen gu-ten Job machen wollen?
Ich bin Informatiker, Hochschullehrender und Forscher aus Leidenschaft. Beide Fragen beschäfti-gen mich in meinem beruflichen Alltag seit Jahren, geprägt auch durch meinen eigenen Bildungshintergrund als FH Alumni sowie Erfahrungen in der industriellen Automobilentwicklung. Im Folgenden nehme ich gerne die Gelegenheit war, mein daraus resultierende Lehrkonzept zu erläutern.
1. Mein Verständnis von Wissenschaftlichkeit
Als Forscher bin ich in der experimentellen Informatik beheimatet, konkret in der künstlichen Intelligenz (KI) und dem maschinellen Lernen (ML), eingebettet in das interdisziplinäre Feld der Data Science. Eine der wichtigsten Erkenntnisse dieser Disziplin ist das sog. “No free lunch theorem” [Wolpert & Macready, 1997]: Es postuliert die generelle Äquivalenz aller selbstlernenden Algorithmen unter der Prämisse, dass über das konkrete Einsatzszenario noch keine Erkenntnisse vorliegen. Dies macht KI und ML zu einer empirischen Wissenschaft: Ohne kontrollierte, wiederholbare Experimente lässt sich keine Aussage über die Leistungsfähigkeit einer Entwicklung treffen.
Entsprechend fusst mein Verständnis von Wissenschaftlichkeit in der Anwendung der wissenschaftlichen Methode [Newton, 1687]. Dieser Zyklus von Experimentieren und Theoriebildung führt zur Erlangung neuer Erkenntnisse [Vardi, 2010]: Das Experiment zeigt potentiell verblüffende Ergebnisse, deren Verständnis und Einordnung ein Update des eignen Modells (Theorie) bedingt. Anhand des neuen Modells gepaart mit der Kreativität eines Forschers (einer “guten Idee”) können neue Hypothesen formuliert werden, welche wiederum in nachfolgenden Experimenten Bestätigung finden müssen, um das Modell zu verifizieren.
Dieser Prozess lässt sich, so die Grundhypothese dieses Lehrkonzepts, von einem Modell der Erkenntnisgewinnung generalisieren auf eines zur Erlangung neuer Entwicklungen und Produkte – also auf ein Vorgehensmodell nicht nur für den wissenschaftlichen, sondern auch für den industriellen Bereich. Auch hier haben wir eine “Forschungsfrage”” zu lösen (das praxisrelevante Problem) und tun gut daran, zielgerichtet auf eine Lösung zuzuarbeiten, anstatt zufällig auszuprobieren (wozu die kontrollierten Experimente dienen).
Ein gutes Beispiel für die gewinnbringende Anwendung dieses Kreislaufs aus Theorie und Praxis, den wir wissenschaftliche Methode nennen, zeigt sich sehr elegant im Paradigma der eScience [Hey et al, 2009], welche mittlerweile breiter als Data Science Bekanntheit erlangt hat. Es ist das Paradigma der “Data-Driven Discovery” – des Herauslesens von Paradigmen und Erkenntnissen aus den Daten selbst, möglichst ohne das Einbringen potentiell falschen Vorwissens. Stellen wir uns etwa folgende Herausforderung aus dem Gebiet des maschinellen Sehens (“computer vision””) vor, für die eine datengetriebene Vorgehensweise erfolgversprechend ist:
Ziel sei die optische Qualitätskontrolle industrieller Erzeugnisse, basierend rein auf Bildern der Erzeugnisse und einem Trainingsdatensatz solcher Bilder mit korrekter menschlicher Entscheidung (“gut” oder “defekt””). Wir können ein solches Modell unter Zuhilfenahme nur minimaler Prämissen rein aus den zusammengehörenden Paaren von Bildern und menschlichen Entscheiden lernen lassen, indem wir eine der vielfältigen Methoden des maschinellen Lernens (etwa: Deep Learning) verwenden. Um die generelle Eignung und spezifischen Einstellungen des gewählten Verfahrens zu eruieren, sind dann kontrollierte Experimente und das Ziehen gut abgesicherter Schlussfolgerungen notwendig – kurz, der Einsatz der wissenschaftlichen Methode.
Das Experimentieren ist so integraler Bestandteil jeder Arbeit in der experimentellen Informatik. Die Herausforderung für Studierende ist, dies von anderen Paradigmen in der Informatik zu unterscheiden, etwa vom Prozess der Softwareentwicklung (der geprägt ist vom möglichst fehlerfreien Einhalten einer gegebenen Spezifikation). Neu hinzu kommt für die Studierenden also der Aspekt der Theoriebildung: Welche Schlüsse lassen sich aus den Beobachtungen ziehen? Was wird hierdurch belegt – und was nicht? Welche gezogenen Konsequenzen waren zwingend – und welche vielleicht eine gute Idee, jedoch vom experimentellen Ergebnis noch nicht einmal impliziert?
Es ist ein Kernanliegen meiner Lehre, den Studierenden diese bislang ungewohnte Denkweise nicht nur einmal nahezubringen, sondern sie so weit zu bringen, diese aufgrund ihrer hohen Relevanz für praktische Ergebnisse auch im Alltag nicht zu vernachlässigen. Dies bedeutet für die meisten Studierenden einen Wechsel der Denkweise, der keinesfalls trivial ist.
2. Kompetenzen wissenschaftlicher Fachpersonen
Eine in meiner Disziplin wissenschaftlich kompetente Fachperson – ein Data Scientist – wendet die wissenschaftliche Methode flächendeckend in seinen Entwicklungsprojekten (d.h., bei der Entwicklung von Datenverarbeitungspipelines, neuen Algorithmen, oder kompletten Produkten und Dienstleistungen von der automatisch erstellten Entscheidungsvorlage bis zum selbstfahrenden Fahrzeug) an. Dabei zeigen sich folgende Schlüsselkompetenzen:
-
Systematik: Experimente werden wiederholbar durchgeführt. Damit das Experimentieren effizient vonstattengeht, gehört dazu ein hoher Grad an Automatisierung mittels schnell und einfach entwickelten “Scripten”. Hier ist also eine Abgrenzung vom typischen Prozess der Softwareentwicklung notwendig.
-
Kreativität: Jedes Experiment ist so designt, dass ein vorhergesagtes Ergebnis entweder eintritt oder nicht (es gibt also einen guten Grund genau für dieses Experiment). Das Kreative liegt im Voraussagen bislang unbeobachteter Ergebnisse aus der bisherigen Theorie in Verbindung mit einer neuen Idee. Im Beispiel der Qualitätsüberwachung oben kann das etwa folgende Hypothese sein: “Ich erkenne bestimmte Arten von Fehlern besser, wenn ich die Bilder zuvor beleuchtungstechnisch normalisiere”.
-
Schlussfolgern: Jedes Ergebnis ist ein gutes Ergebnis, da es Schlussfolgerungen auf die eigenen Annahmen (Voraussagen) zulässt: Die “gute Idee” kann dadurch erhärtet oder – unter bestimmten Umständen – falsifiziert werden. Schlussfolgerndes Denken trägt auch entscheidend zur Diskursfähigkeit bei, welche der eigenen Arbeit später im beruflichen Kontext erst das notwendige Gewicht verleiht, um Gehör zu finden: “Wer schreibt, der bleibt”” gilt nicht mehr nur für Wissenschaftler und Intellektuelle; jeder Ingenieur muss in der heutigen Meetingkultur bereit und fähig sein, seine Lösungsansätze in der Diskussion nach innen (gegenüber Peers und Vorgesetzten) und aussen (gegenüber Kunden) zu vertreten.
-
Recherchieren: Wissenschaftliches Arbeiten zeichnet sich dadurch aus, dass das Rad nicht neu erfunden werden muss (“Standing on the shoulders of giants”” [Newton, 1676]). Hierzu kennt die Fachperson die relevante wissenschaftliche Literatur, liest sich gezielt weiter ein und setzt so den für den aktuellen Auftrag passenden Kontext (“State of the Art””). Was dem Wissenschaftler seine “Papers”” sind, mag für den Ingenieur in der Wirtschaft ein technisches Whitepaper sein – die notwendigen Kompetenzen bleiben die gleichen: Schnelles Erfassen wesentlicher Inhalte, daher Mut zum Querlesen mit dem Ziel der Bewertung der Relevanz.

Abbildung 1: Virales Internet-Meme zur Bedeutung des Schreibens.
- Schreiben: Das Ergebnis aus Experiment und modifiziertem Verständnis wird in Form eines technischen Berichts niedergeschrieben – zum einen als Dokumentation der eigenen Arbeit, zum anderen als eigener Beitrag zum zuvor recherchierten State of the Art (siehe auch Abb. 1 oben aus [Savage, 2012]). In Ergänzung zu den Argumenten im Punkt “Schlussfolgern”” hilft diese wissenschaftliche Schlüsselkompetenz in nahezu jedem Berufsalltag in Folge der Verschriftlichung vieler Kommunikationswege (Emails, Instant Messaging): Knappes, klares, verständliches Schreiben, angenehm formuliert und inhaltlich überzeugend.
3. Transparente Einordnung gegenüber den Studierenden
Obiges Verständnis von Wissenschaftlichkeit zieht sich also ganz grundsätzlich durch den gesamten Entwicklungsprozess jeder Anwendung in der künstlichen Intelligenz und dem maschinellen Lernen, da die dazugehörigen Kompetenzen die direkte Verbindung zwischen der “scientific method” als Prinzip und dem konkreten Entwickeln von Lösungen darstellen. Umso wichtiger ist es, den Studierenden diesen Wissenschaftler/Profi deutlich vor Augen zu stellen. So wird transparent gemacht, wie hier etwas “theoretisches”” erst zum Ermöglicher der Praxis wird.
Ein wesentliche Rolle spielen hierbei Gespräche mit den Studierenden im (und oft fortgesetzt am Rande des) Unterrichts, die sich mehrmals pro Semester an taktisch dafür vorgesehenen Beispielen entzünden: Warum sollte man schreiben (siehe auch meine Blogposts als Destillate solcher Diskussionsrunden: Release your thoughts – publish as you go , Writing a draft)? Was ist das richtige Verhältnis von Theorie zu Praxis (siehe auch On the use of examples in learning , The role of novel ideas in neural network research & applications)? Wozu braucht es Wissenschaftlichkeit in einer praxisnahen Ausbildung (siehe auch Doing applied science)?
Gerade mit Informatikstudierenden muss letzteres – die Einordnung der Rolle von Wissenschaftlichkeit (“science””) gegenüber einem fatalen Missverständnis von Anwendungsorientierung (“applied””) – immer wieder erfolgen, anstatt als automatisch geschehend angenommen zu werden. Dem Missverständnis zufolge sei Wissenschaftlichkeit das, was im “Elfenbeinturm”” geschähe, also fernab betrieblicher Praxis und daher ohne Relevanz. Demgegenüber entdecken wir im Unterricht und den begleitenden Laborübungen gemeinsam, dass Kenntnis wissenschaftlicher Ergebnisse nicht nur auf Jahre frisches Wissen sicherstellt; vielmehr garantiert Arbeiten anhand der wissenschaftlichen Methode in unserer Disziplin die Entwicklung relevanter und praxistauglicher Lösungen – sowohl im Betrieb als auch in der Forschung. “Applied science”” ist demnach das Anwenden der wissenschaftlichen Methode zur Lösung eines bislang ungelösten, konkreten Use-Cases.
4. Vermittlung der Kompetenzen im Unterricht
Mein Lehrkonzept stellt Wissenschaftlichkeit also als besten Weg zu einer guten Praxis vor, konkretisiert anhand von fünf Kompetenzen, die es zwingend zur Entwicklung von Anwendungen der künstlichen Intelligenz und des maschinellen Lernens braucht. Dies spielt auf unterschiedliche Art in verschiedenen Lehrveranstaltungen eine herausragende Rolle; konkret beziehe ich mich nun auf die Folgenden:
-
Vorlesungen: “Künstliche Intelligenz” (Wahlmodul letztes Studienjahr B.Sc. Informatik), “Machine Learning” (technisch-wissenschaftliches Vertiefungsmodul im MSE)
-
Seminar: “Artificial Intelligence (AI) Seminar” (erweiterte Lehrveranstaltung im MSE)
-
Thesis Projects: Projekt- und Bachelorarbeiten im B.Sc. Informatik, MSE-Vertiefungsarbeiten
In Vorlesungen thematisiere ich den Produktentwicklungsprozess (als das gesamte fachspezifische Arbeiten und Entwickeln beschreibender Begriff der Automotive-Branche entlehnt) direkt z.B. in Lehreinheiten zum fachspezifischen Vorgehensmodell oder experimentellen Design (siehe Abb. 2).
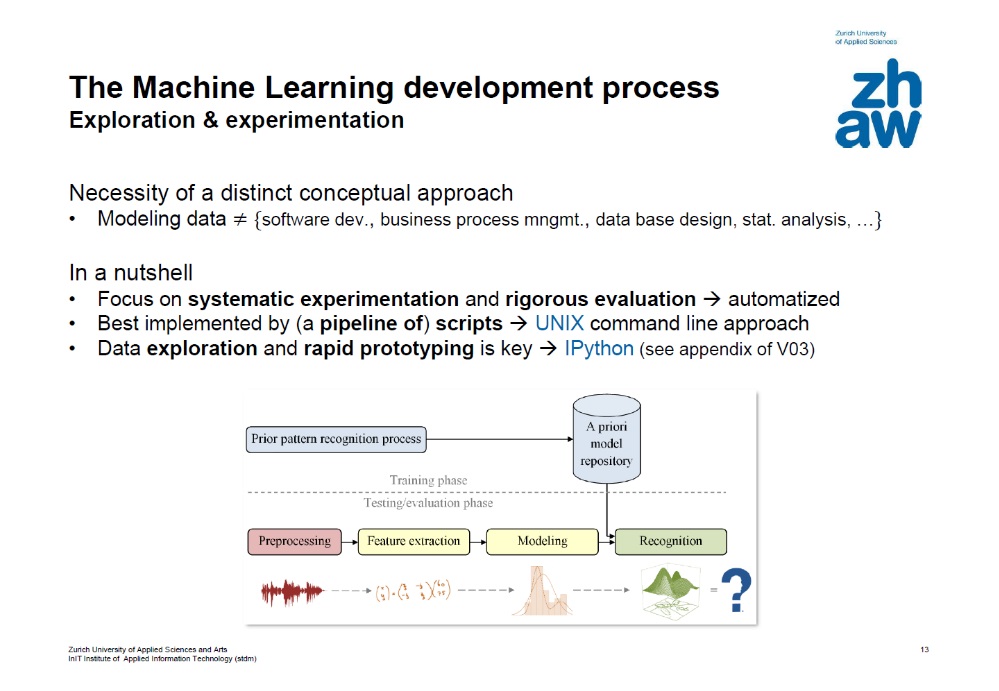
Abbildung 2: Folie 13 aus den Kursunterlagen V02 zu TSM_MachLe (“Machine Learning” im MSE).
Ziel ist hier, die Studierenden an das dahinerliegende Denkmodell heranzuführen, dass sie dann in Laborübungen selbständig anwenden werden.

Abbildung 3: Folie 25 aus V01 (Einblick in Ereignisse aus der Forschungslandschaft) sowie Folie 21 aus V07 (mit einem Recherche- und Meinungsbildungsauftrag) der Kursunterlagen zu “Künstliche Intelligenz”.
Die Wichtigkeit von offenen Diskussionen mit Studierenden wurde im vorangegangenen Abschnitt bereits genannt. Beides (Frontalunterricht und Diskussion) dient der vorbereitenden Konfrontation der Studierenden mit einer Denk- und Arbeitsweise, die Ihnen aus anderen Subdisziplinen der Informatik heraus weniger geläufig ist (siehe auch den ersten Bulletpoint in Abb. 2). Beides wird immer wieder ergänzt durch den Frontalunterricht unterbrechende Arbeitsaufträge an die Teilnehmenden, sowie motivierende Einblicke in das Geschehen der relevanten akademischen Forschungscommunity, wie beispielhaft in Abb. 3 gezeigt wird. Diese Beispiele zeigen (etwa dasjenige der «Neural Information Processing Systems» Konferenz 2016, im Bild links) eine attraktive Vernetzung von Wissenschaft, Forschung und Industrie (an der Konferenz: Der grösste Teil der mehr als 5’000 Teilnehmer dieser wichtigsten aller akademischen Treffen im Bereich Deep Learning arbeitet in der Industrie).
Intensiver lassen sich die fünf Schlüsselkompetenzen – Systematik, Kreativität (bzw. Vorhersagefähigkeit), Schlussfolgern, Recherchieren und Schreiben – in konkreten praktischen Forschungs- und Entwicklungsaufträgen vermitteln, wie sie natürlicher Weise in Seminaren und Projektarbeiten auftreten. Im AI Seminar setzen sich die Studierenden mit einem Thema Ihrer Wahl aus der wissenschaftlichen Literatur auseinander. Begleitet wird dies durch vier zu schreibende Blogposts, die zur expliziten, kritischen Auseinandersetzung mit der gewählten Literatur einladen sowie den eigenen Schreibprozess anstossen. Zur Diskursfähigkeit trägt bei, dass die Studierenden sich mit obligatorischen Kommentaren und Repliken zu Ihren Beiträgen daran gewöhnen, ihre Überzeugungen überzeugend (sic!) zu artikulieren.
In Thesis Projects kommt dieser Aspekt des Recherchierens und Schreibens zusammen mit dem in den Vorlesungen eingeübten kritischen – schlussfolgernden – Denken. Letzteres operiert auf experimentellen Ergebnissen, die über systematische und vorausplanende Versuche erlangt wurden. Lediglich Kreativität als solche zu vermitteln ist hier trickreich; ich behelfe mir durch “was wäre wenn”-Planspiele mit einem Pool vorhandener Ideen, anhand derer die Studierenden das Vorausplanen von Versuchsergebnissen unabhängig vom Ideen-haben einüben können: Die Ideen kommen von den Betreuern (oft bitte ich einen weiteren Kollegen zur Formung eines interdisziplinären Teams hinzu), die Implementierung und Erforschung ihrer Nützlichkeit obliegt den Studierenden.
5. Überprüfung in Leistungsnachweisen
Vorlesungen enden bei mir ab einer gewissen Teilnehmerzahl – gerade die beiden genannten Veranstaltungen vereinen deutlich überdurchschnittlich viele studentische Wahlen auf sich – mit schriftlichen Prüfungen. Hierbei spielt das Verstehen (Erklären, aber vor allem auch das Argumentieren) eine wesentliche Rolle. Ich überprüfe dieses sowohl mittels ausarbeitungsintensiver Multiple-Choice Fragen als auch mit Freitextfragen, in denen eine Antwort innert ein bis zwei Sätzen präzise auf den Punkt gebracht werden soll (beispielsweise eine Begründung für ein Beispielhaft skizziertes Verhalten eines ausgewählten Verfahrens).
[… examples from real exams ommitted …]
Im Seminar und den praktischen Arbeiten zeigt sich die Fokussierung auf obiges Kompetenzprofil in der Gewichtung der einzelnen Aspekte: Ob Programmcode entsteht und wie dieser aussieht, spielt kaum eine Rolle; wesentlich ist die schriftliche Aufbereitung (50%), in welcher wiederum die empfängerspezifische Darlegung einer stringenten Aussage und deren argumentative Untermauerung (inkl. Referenzen) erfolgsentscheidend ist (siehe auch Advice for prospective students , Doing applied science).
Erfolgreichen Studierenden steht es Dank mehrerer interdisziplinärer Initiativen des Datalabs, an denen ich beteiligt sein durfte, künftig offen, den höchsten Nachweis von Wissenschaftlichkeit direkt im Anschluss an das Masterstudium an der ZHAW hier im Rahmen einer Promotion zu erbringen. Unter den bald 5 Doktoranden des von mir stellvertretend geleiteten Schwerpunkts «Information Engineering» ist bereits einer mit ZHAW-Bachelordiplom.
Referenzen
[Wolpert & Macready, 1997] David H. Wolpert, William G. Macready, “No Free Lunch Theorems for Optimization”. IEEE Transactions on Evolutionary Computation 1, 67, 1997:
“We have dubbed the associated results No Free Lunch theorems because they demonstrate that if an algorithm performs well on a certain class of problems then it necessarily pays for that with degraded performance on the set of all remaining problems.”
[Newton, 1687] Isaac Newton, “Philosophiae Naturalis Principia Mathematica””. 1687.
[Vardi, 2010] Moshe Y. Vardi, “Science has only two legs”. Communications of the ACM, Vol. 53 No. 9, Page 5, 2010.
[Hey et al., 2009] Tony Hey, Stewart Tansley, Kristin Tolle, “The Fourth Paradigm: Data-Intensive Scientific Discovery”. Microsoft Research, 2009.
[Newton, 1676] Isaac Newton, “Letter from Sir Isaac Newton to Robert Hooke”. 1676.
[Savage, 2012] Adam Savage, online, 2012.